Efficiency geek: zeroing data in C/C++, optimisation
On the SuperCollider developer list we were discussing what was the most efficient way to set a block of floating-point data to zero. So I've run a test... here's the results.
I wrote a plugin which repeatedly clears a block of 512 floating-point values by calling SuperCollider's Clear() macro, and then ran 10 of these plugins in a synth. By changing what happens inside the macro I could test different approaches, and see the CPU load in each case.
This shows the different ways that I used to clear the data:
// (1) SuperCollider's old code, hand-optimised for powerpc.
// requires 8-byte alignment, annoyingly.
if ((numSamples & 1) == 0) {
double *outd = (double*)out - ZOFF;
LOOP(numSamples >> 1, ZXP(outd) = 0.; );
} else {
out -= ZOFF;
LOOP(numSamples, ZXP(out) = 0.f; );
}
// (2) for-loop method using array indexing:
int i;
for(i = 0; i < numSamples; ++i)
out[i] = 0.f;
// (3) for-loop method using pointer postincrement:
int i;
float *loc = out;
for(i = 0; i < numSamples; ++i)
*(loc++) = 0.f;
// (4) for-loop method using pointer preincrement:
int i;
float *loc = out - 1;
for(i = 0; i < numSamples; ++i)
*(++loc) = 0.f;
// (5) a do-while loop:
int i = numSamples;
do{
out[--i] = 0.f;
}while(i != 0);
// (6) a duff's device using pointer postincrement:
float *loc = out;
DUFF_DEVICE_8(numSamples, *(loc++)=0.f;);
// (7) a duff's device using pointer preincrement:
float *loc = out - 1;
DUFF_DEVICE_8(numSamples, *(++loc)=0.f;);
// (8) memset'ing the data to a char value of zero:
memset(out, 0, numSamples * sizeof(float));
// (9) bzero, which sets character data to a value of zero:
bzero(out, numSamples * sizeof(float));
// (10) for-loop method using pointers and manual unrolling:
int i;
float *loc = out;
for(i = numSamples >> 2; i != 0; --i){ // Unroll into blocks of four
*(loc++) = 0.f;
*(loc++) = 0.f;
*(loc++) = 0.f;
*(loc++) = 0.f;
}
// These two "if"s handle the remainder, if not divisible exactly by four
if(numSamples & 1){
*(loc++) = 0.f;
}
if(numSamples & 2){
*(loc++) = 0.f;
*(loc++) = 0.f;
}
These methods come in two groups: the semantically-correct ones (the for-loops and do-loops, plus the Duff's device) which treat a float as a float; and the hacky ones (memset, bzero, the double-trick) which make use of our knowledge that the binary representation will turn out to be the same. The C/C++ standards don't guarantee that the binary representation will be the same, so some would say these are dangerous approaches. However, the IEEE floating-point standards specify that all-zero-bits equates to zero, so on any machine using IEEE floating-point then this is definitely OK.
And these are the two systems I tested on:
- Mac OSX 10.4.11, 1 GHz PPC G4
- Asus Eee, Xandros Linux, 900 MHz Intel clocked at 630 MHz
Compiled the plugin using ordinary (non-debug) compiler settings from SuperCollider build scripts (on Mac this uses -Os, on Linux -O3). Results:
| Method | Mac PPC | Linux Intel |
|---|---|---|
| 1, sc3 | 67 % | 58 % |
| 2, for, array | 31 % | 75 % |
| 3, for, post | 31 % | 51 % |
| 4, for, pre | 73 % | 75 % |
| 5, do-while | 32 % | 74 % |
| 6, duff's, post | 35 % | 56 % |
| 7, duff's, pre | 31 % | 48 % |
| 8, memset | 11 % | 44 % |
| 9, bzero | 11 % | 44 % |
| 10, unrolled for | 32 % | 51 % |
Some surprises here. One is how much more efficient memset/bzero is than other standard methods. (The optimising compiler converts memset to bzero on my machines, which is why their results are the same.)
Also the strong inefficiency of the preincrementing for-loop method. It's possible that the compiler automatically converts some types of loop into a Duff's device, which would explain why there's a strange pattern of fastness and slowness in the standard loops with the Duff's device as a lower limit on their efficiency. The manual unrolling (method 10) is no help either!
SC's method seems poor on both systems, despite apparently being designed for ppc. (The original author has indeed said that the code in that header-file is getting out-of-date...)
I read that bzero is nonstandard so it would look like one good way to proceed, and pretty easy to do, is to use memset(), but keep in mind that you might not be able to use it on systems with non-IEEE fp.
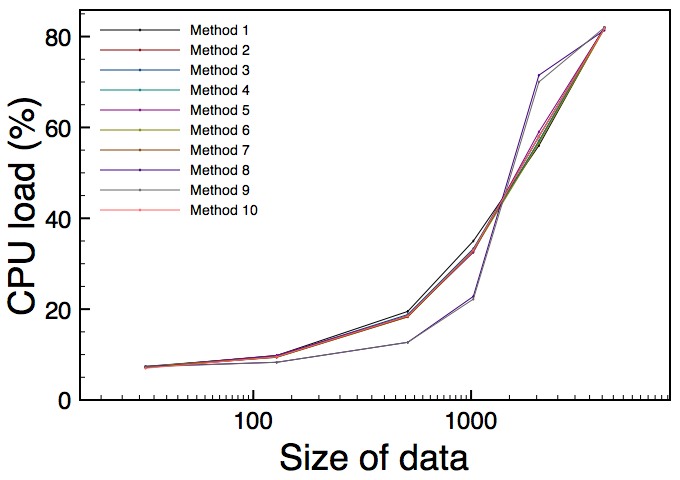
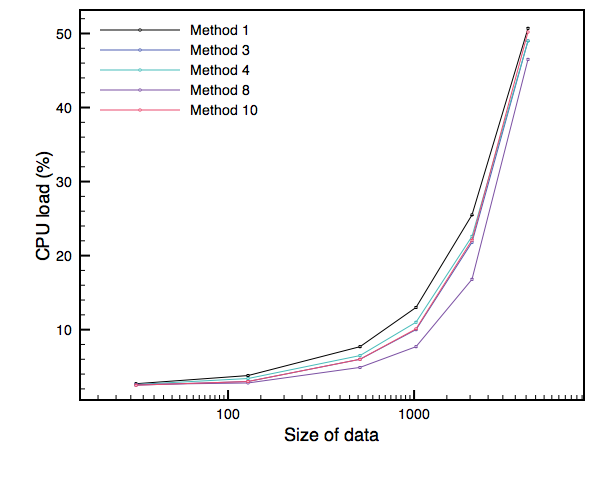
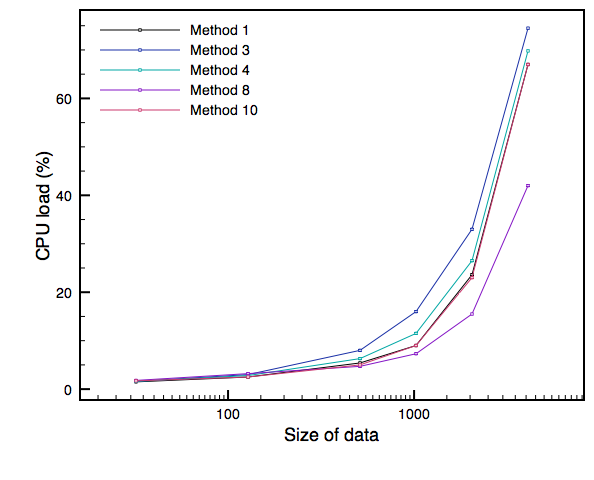
These graphs show the results for different data sizes, within the range we most care about for SC:
| Mac, Intel Core Duo | Mac, PPC G4 | Intel Linux (Eee) |
|---|---|---|
|
|
|
Note that each graph is produced with a different number of parallel UGens - I had to push it up to 500 to get significant CPU usage on the Core Duo! The clear tendency over all three graphs is for memset to have the edge, although there's some interesting alternation in the Core Duo graph.
Reminder of the two important rules: (1) take all benchmarks with a big pinch of salt; (2) don't optimise until you can prove that you should do. These benchmarks are specific to UGen plugins running in SuperCollider, YMMV.